-
1.4 Database design and programming데이터베이스 시스템 2024. 10. 7. 12:21
Analysis 분석
데이터베이스 설계는 테이블, 열, 데이터 유형, 인덱스와 같은 데이터베이스 객체를 명시하고 개발하는 과정이다.
대규모 데이터베이스의 경우 3가지 단계로 나뉜다:
- 분석(Analysis)
- 논리적 설계(Logical design)
- 물리적 설계 (Physical design)
분석 단계에서는 특정 데이터베이스 시스템에 구애받지 않고 데이터베이스 요구 사항을 명시한다. 요구 사항은 엔터티(Entity), 관계(Relationship), 속성(Attribute)으로 표현된다. 엔터티는 사람, 장소, 활동 또는 사물을 의미하고, 관계는 엔터티 간의 연결을 나타내며, 속성은 엔터티의 설명적 속성이다.
분석 단계는 여러 가지 다른 이름으로 불리기도 하는데, Ex: 개념적 설계(conceptual design), 엔터티-관계 모델링(entity-relationship modeling), 요구 사항 정의(requirements definition) 등이 있다.
엔터티, 관계, 속성은 ER 다이어그램(Entity-Relationship Diagram)으로 표현된다:
- 엔터티는 둥근 모서리를 가진 사각형. 사각형 상단에 이름 표시.
- 관계는 사각형 간의 선
- 속성은 사각형 내부, 엔터티 이름 아래에 있는 텍스트
ER 다이어그램은 보통 엔터티, 관계, 속성에 대한 텍스트 설명으로 보충된다.

ER Diagram Logical design 논리적 설계
논리적 설계 단계는 데이터베이스 요구 사항을 특정 데이터베이스 시스템에 맞게 구현하는 과정이다.
관계형 데이터베이스 시스템의 경우, 논리 설계는 엔터티, 관계, 속성을 테이블, 키, 열로 변환한다.
키는 테이블의 각 행을 식별하는 데 사용되는 열이다. 테이블, 키, 열은 SQL의 CREATE TABLE 문으로 정의된다.
논리적 설계는 테이블 다이어그램으로 묘사된다. 테이블 다이어그램은 ER 다이어그램과 유사하지만 더 자세하다:
- 직각 모서리를 가진 사각형은 테이블을 나타낸다. 테이블 이름은 사각형의 상단에 표시된다.
- 사각형 내부의 텍스트는 테이블 이름 아래에 열을 나타낸다.
- 점(●)은 키 열을 나타낸다.
- 테이블 간 화살표는 키를 참조하는 열을 나타내며, 화살표의 꼬리는 해당 열과 맞닿아 있고, 화살표는 키를 포함하는 테이블을 가리킨다.
SQL로 정의되고 테이블 다이어그램으로 묘사된 논리적 설계를 데이터베이스 스키마(schema)라고 한다.
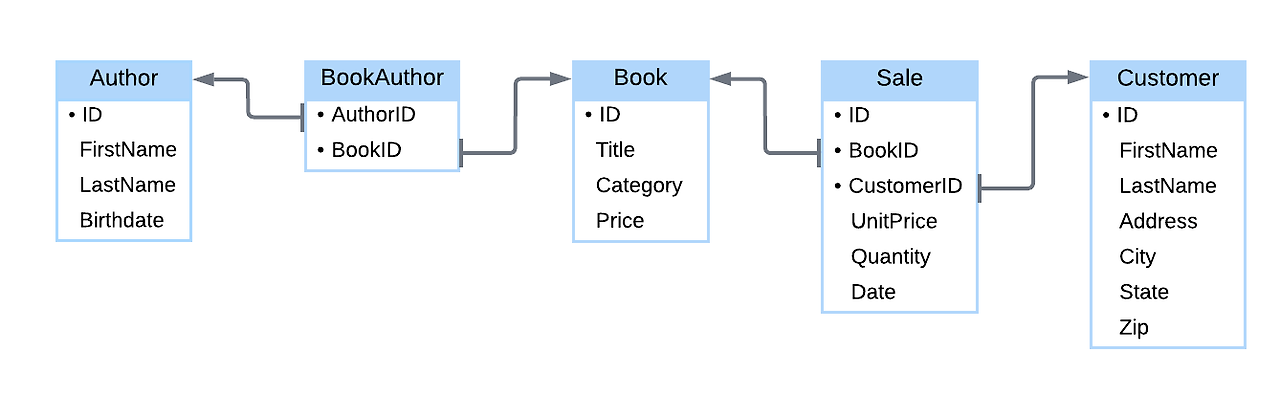
Table Diagram Physical design 물리적 설계
물리적 설계 단계에서는 인덱스를 추가하고 테이블이 저장 매체에 어떻게 구성될지를 지정한다. Ex: 테이블의 행은 특정 열의 값을 기준으로 정렬되어 정렬된 순서대로 저장될 수 있다. 물리적 설계는 CREATE INDEX와 같은 SQL 문으로 정의되며, 논리적 설계와 마찬가지로 특정 데이터베이스 시스템에 종속적이다.
물리적 설계 다이어그램은 흔히 사용되지 않는다.
관계형 데이터베이스에서는 논리적 설계와 물리적 설계가 쿼리에 미치는 영향이 다르다. 논리적 설계는 쿼리 결과에 영향을 미치지만, 물리적 설계는 쿼리 처리 속도에만 영향을 미치고 쿼리 결과에는 영향을 미치지 않는다. 물리적 설계가 쿼리 결과에 영향을 미치지 않는다는 원칙을 데이터 독립성(data independence)이라고 한다.
데이터 독립성 덕분에 데이터베이스 설계자는 응용 프로그램을 변경하지 않고도 쿼리 성능을 조정할 수 있다. 데이터베이스 설계자가 인덱스나 행 순서를 수정하면 애플리케이션의 실행 속도는 빨라지거나 느려질 수 있지만, 쿼리 결과는 항상 동일하게 유지된다.
데이터 독립성은 관계형 데이터베이스의 주요 이점 중 하나이며, 1980년대에 관계형 기술이 빠르게 도입된 이유 중 하나이다.
Programming 프로그래밍
데이터 독립성 덕분에 관계형 데이터베이스 애플리케이션은 물리적 설계가 완료되기 전에 프로그래밍될 수 있다. 애플리케이션의 실행 속도는 느릴 수 있지만, 올바른 결과를 생성할 수 있다.
SQL은 관계형 데이터베이스의 표준 쿼리 언어이지만 중요한 프로그래밍 기능이 부족하다. Ex: 대부분의 SQL 구현은 객체 지향적이지 않다. 따라서 데이터베이스 프로그램을 작성할 때는 보통 SQL을 C++, Java, Python과 같은 범용 프로그래밍 언어와 함께 사용한다.
SQL을 범용 언어와 함께 사용하는 것을 간소화하기 위해 데이터베이스 프로그램은 일반적으로 응용 프로그래밍 인터페이스(API)를 사용한다. API는 호스트 프로그래밍 언어와 데이터베이스를 연결하는 절차나 클래스의 라이브러리이다. 호스트 언어는 라이브러리 절차를 호출하고, 이 절차는 데이터베이스 연결, 쿼리 실행, 결과 반환 등의 세부 사항을 처리한다. Ex: JDBC는 관계형 데이터베이스에 접근할 수 있는 Java 클래스의 라이브러리이다.
[출처: zyBooks]
UH at manoa online class
'데이터베이스 시스템' 카테고리의 다른 글
6.2 Simple Functions (0) 2024.10.22 6.1 Special operators and clauses (0) 2024.10.22 1.3 Query languages (0) 2024.10.05 1.2 Database systems (0) 2024.10.05 1.1 Database basics (0) 2024.10.05